Basics
The Spark engine uses a DAG (Directed Acyclic Graph) to keep track of transformations and to lazily execute actions. A transformation includes map, ReduceByKey, GroupByKey, JoinByKey, etc. and actions include Count, Take, and ForEach. Transformations just build the DAG and actions lead to the actual execution. If necessary, you can store intermediate transformations in memory using persistance feature of Spark.
Shuffle processes can also occur but can be expensive due to storage costs (it might spill into disk and be slow). Spark can also perform dynamic allocation, allowing resources to be returned to pools.
Spark is designed for parrallelized execution. Issues with parrallelism includes making sure that the code is properly split up and that skew doesn’t occur (operation on a single core). As will be explained, behavior on local host may be different than production.
Useful
Transformations and Actions
- map(func): Applies func to all elements in the RDD and returns a new RDD. This transforms aa element of length n to another element of length n.
- flatmap(func): Applies func to all elements in the RDD but can return more than one object. This tranforms an element of length n to one of length 0, 1, or more.
- filter(func): Keep elements that func returns true for.
- GroupBy(func): This is one aggregate function that allows you to group rows together based on some column value.
- take(#): Returns the first # elements in the RDD.
For groupBy() it is common to follow with an agg() function. You can use the PySpark functionals to
Manipulations of DataFrames (RDDS)
- spark.read.load(filePath, format=”csv”,sep=”,”,inferSchema=”true”,header=”true”): Load in RDD
- show(): Display all the data
- withColumnRenamed(curColName,newColName): Renames a column of the data frame
- select([col1,col2,…]): Returns RDD with the selected columns
- sort(col): Returns the RDD sorted along the specific (default ascending) to do descending import
from pyspark.sql import functions as Fand wrap F.desc(colname). - withColumn(col,F.col(col).cast(IntegerType())): replace the column with a specifically cast type
- alias(name): Assign a column produced by the agg() command as a specific alias.
Aggregations and Join
- join()
Using Spark in Python
! pip install pyspark
from pyspark import SparkContext, SparkConf
Initialization
conf = SparkConf().setAppName(appName).setMaster(master)
sc = SparkContext(conf=conf)
The SparkContext tells Spark how to access the cluster. The appName parameter is the name of the application to show on the cluster UI and master is the Spark, Mesos, or YARN cluster URL. You will want to launch the application with spark-submit instead of hard-coding.
Abstractions (Components) in Apache Spark
Spark applications use a driver program that runs the main() which executes various operations in parallel across a cluster.
Resilient Distributed Dataset (RDD)
An RDD is a collection of elements partitioned across nodes of a cluster that can be operated in parallel. They can recover from failure and can be persisted in memory in Spark.
There are two ways to create an RDD:
- Parrallelize an existing collection in the driver program
- Referencing a dataset in an external storage system (e.g. HDFS, HBase, or any data source offering a Hadoop InputFormat)
data = [1, 2, 3, 4, 5]
distData = sc.parallelize(data,10) # 10 is the number of partitions to cut the data set into
distData.reduce(lambda a, b: a + b) # a parallel operation performed on data array
Important: You specify the number of partitions and typically you want 2-4 partitions for each CPU in your cluster.
External Datasets
External Dataset Examples: Amazon S3, HBase, Cassandra, HDFS, etc.
Important Commands
- textFileCommand(): Read in external file or specific text file.
- wholeTextFiles(): Read in (filename,content) pairs from a directory of small text files
You can read in a text file using the sc.textFile(filename) command where filename can be replaced by the local path on the machine to the external storage (e.g “hdfs://”). Once created, the dataset can be operated on using dataset operations like map() and reduce(). By default, Spark will allocate 1 partition per 128MB block, but that can be specified by the second parameter.
RDD Operations
There are two types of operations supported by RDDs: transformations (e.g. map) or actions (e.g. reduce). All transformations are lazy in that they do not compute the results right away but the transformations are remembered and computed whenever an action requires a result to be returned to the driver program.
This is useful for efficiency, but each transformed RDD may be computed each time the action is called. To stop, this you can use persist or cache in which Spark will keep the elements around the cluster for a much faster access the next time you query.
Basic example
lines = sc.textFile("data.txt") # load in (but not actually just point)
lineLengths = lines.map(lambda s: len(s)) # add map to computation graph
lineLengths.persist() # designate lineLengths to be saved into memory AFTER the first time that it is used
totalLength = lineLengths.reduce(lambda a, b: a + b) # perform an action, so 1) partition data, 2) load, 3) map and persist, 4) reduce
Functions in Spark
There are 3 recommended ways to pass functions into Spark.
- Lambda expressions (e.g.
lambda s: len(s)) - Local defs in Spark
- Top-level functions in a module
#1 and #2 are easy, but when using #3 (like if you have a class whose function you are calling) then you cannot reference the class in the function otherwise the whole object will be sent to the cluster. To avoid this, copy whichever field you need into a local variable instead of accessing it externally and then pass in the function.
Closures in Spark
It is important to understand the lifecycle and scope of variables in Spark.
Local vs Cluster Modes
To execute jobs, Spark firsts breaks up the RDD operations into tasks which are executed by the executor. Prior to execution, Spark computes the task’s closure which are variables and methods that need to be visible for the executor to perform its computations on the RDD. Because the closure is sent to each executor you may encounter issues, such common with mutable variables (i.e. no longer atomic.).
A common example is with a counter that references a global variable. The global variable will be sent to each executor within the closure as a copy, thus, if all executors update the variable, you will see that it actually doesn’t actually count correctly. Instead, an Accumulator should be used.
How to correctly print something
rdd.take(NUMBER_TO_PRINT).foreach(println)
Shared Variables
Shared variables allow the programmer to share information across tasks or between the tasks and the driver programs. There are two types:
- Broadcast: Cache a value in memory on all nodes
- Accumulators: Variables that operations apply to (e.g. sum or counters)
Important Snippets
This section covers small, important snippets that could be of use.
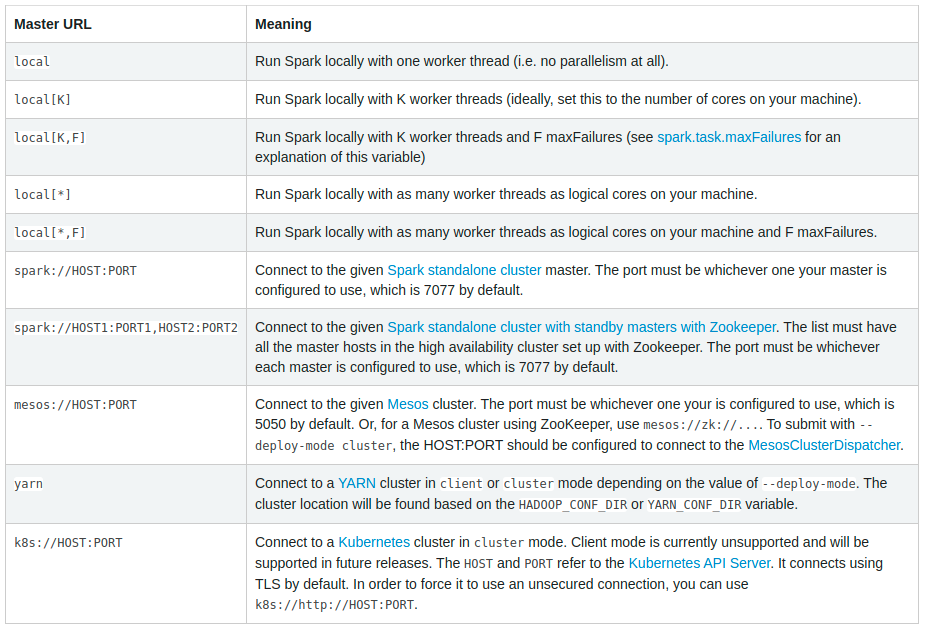
Master URLS
Relevant Topics: initialization.
The Master URL can be a Spark, Mesos, or YARN Cluster URL. The following image can be useful as a guide to knowing what is what.